Comparing Database Topic Coverage
2026-02-17
Source:vignettes/citesource_vignette_db-topic-coverage.Rmd
citesource_vignette_db-topic-coverage.RmdAbout this vignette
CiteSource can be used to examine topical overlap between databases. In this example, we are interested in the overlap among databases, both multi-disciplinary and subject-specific, for the literature on the harmful effects of gambling addiction. To assess this, we ran a very specific search for the term “gambling harm*” in the title and abstract fields of the following databases: Lens, Scopus, Criminal Justice Abstracts, PsycInfo and Medline.
Installation of packages and loading libraries
Use the following code to install CiteSource. Currently, CiteSource lives on GitHub, so you may need to first install the remotes package. This vignette also uses functions from the ggplot2 and dplyr packages.
Import files from multiple sources
Users can import multiple RIS or bibtex files into CiteSource, which the user can label with source information such as database or platform.
#Import citation files from folder
citation_files <- list.files(path= "topic_data", pattern = "\\.ris", full.names = TRUE)
#Read in citations and specify sources. Note that labels and strings are not relevant for this use case.
citations <- read_citations(citation_files,
cite_sources = c("crimjust", "lens", "psycinfo", "pubmed", "scopus"),
tag_naming = "best_guess")
#> Import completed - with the following details:
#> file cite_source cite_string cite_label
#> 1 20221207_gambling-harms_crimjust_41.ris crimjust <NA> <NA>
#> 2 20221207_gambling-harms_lens_49.ris lens <NA> <NA>
#> 3 20221207_gambling-harms_psycinfo_124.ris psycinfo <NA> <NA>
#> 4 20221207_gambling-harms_pubmed_176.ris pubmed <NA> <NA>
#> 5 20221207_gambling-harms_scopus_255.ris scopus <NA> <NA>
#> citations
#> 1 41
#> 2 49
#> 3 124
#> 4 176
#> 5 255Deduplication and source information
CiteSource allows users to merge duplicates while maintaining information in the cite_source metadata field. Thus, information about the origin of the records is not lost in the deduplication process. The next few steps produce the dataframes that we can use in subsequent analyses.
#Deduplicate citations. This yields a dataframe of all records with duplicates merged, but the originating source information maintained in a new variable called cite_source.
unique_citations <- dedup_citations(citations)
#Count number of unique and non-unique citations from different sources and labels.
n_unique <- count_unique(unique_citations)
#For each unique citation, determine which sources were present
source_comparison <- compare_sources(unique_citations, comp_type = "sources")Plot heatmap to compare source overlap
Heatmap by number of records
A heatmap can tell us the total number of records retrieved from each database, and can be used to compare the number of overlapping records found in each pair of databases. In this example, we can see that Scopus yielded the highest number of records on gambling harms, and Criminal Justics Abstracts the least.
#Generate source comparison heatmap
plot_source_overlap_heatmap(source_comparison)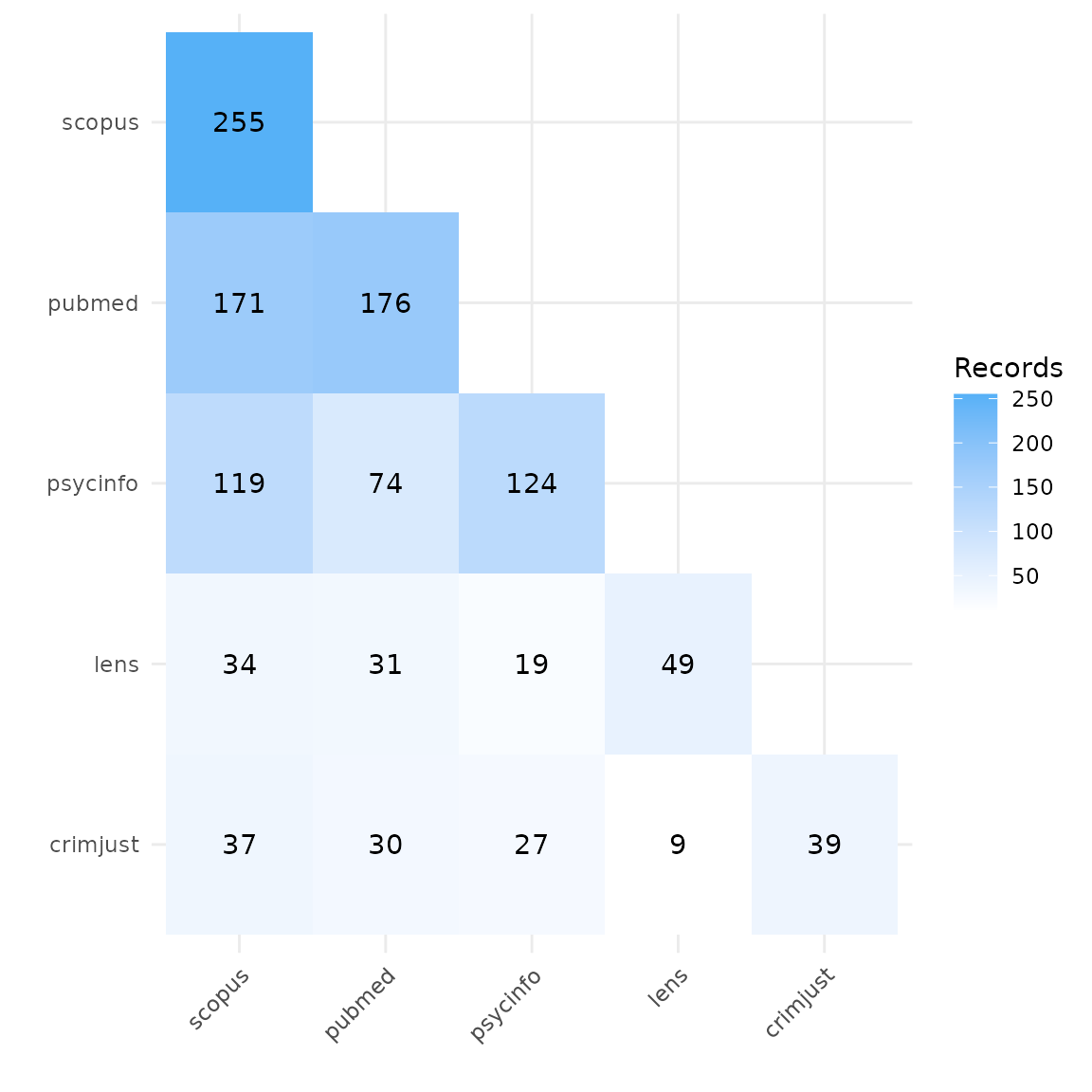
Heatmap by percentage of records
Another way of visualizing this is a heatmap with percent overlap. We
can use the plot_type argument to produce a percentage
heatmap as follows. The total number of records appears in gray. The
percentages indicate the share of records in a row also found in a
column. For example, here we see that 67% of the records in Scopus were
also found in PubMed. Conversely, 97% of records in PubMed were found in
Scopus.
#Generate heatmap with percent overlap
plot_source_overlap_heatmap(source_comparison, plot_type = "percentages")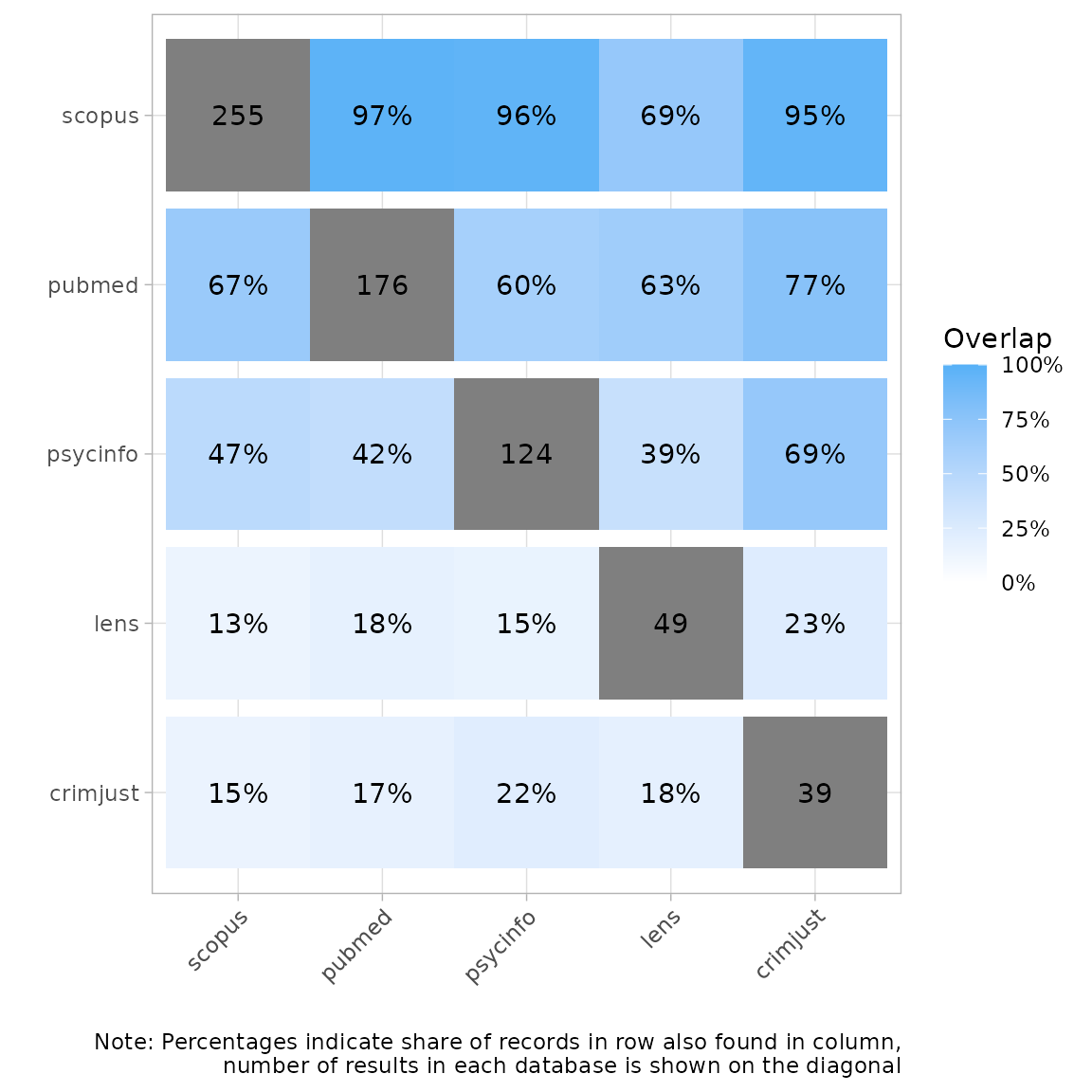
Plot an upset plot to compare source overlap
An upset plot is another way of visualizing overlap and provides a bit more detail about the number of shared and unique records. Here, we can see that Scopus had the most unique records not found in any other database (n=35), and Criminal Justice Abstracts only had one unique record. Six records were found in every database.
#Generate a source comparison upset plot.
plot_source_overlap_upset(source_comparison, decreasing = c(TRUE, TRUE))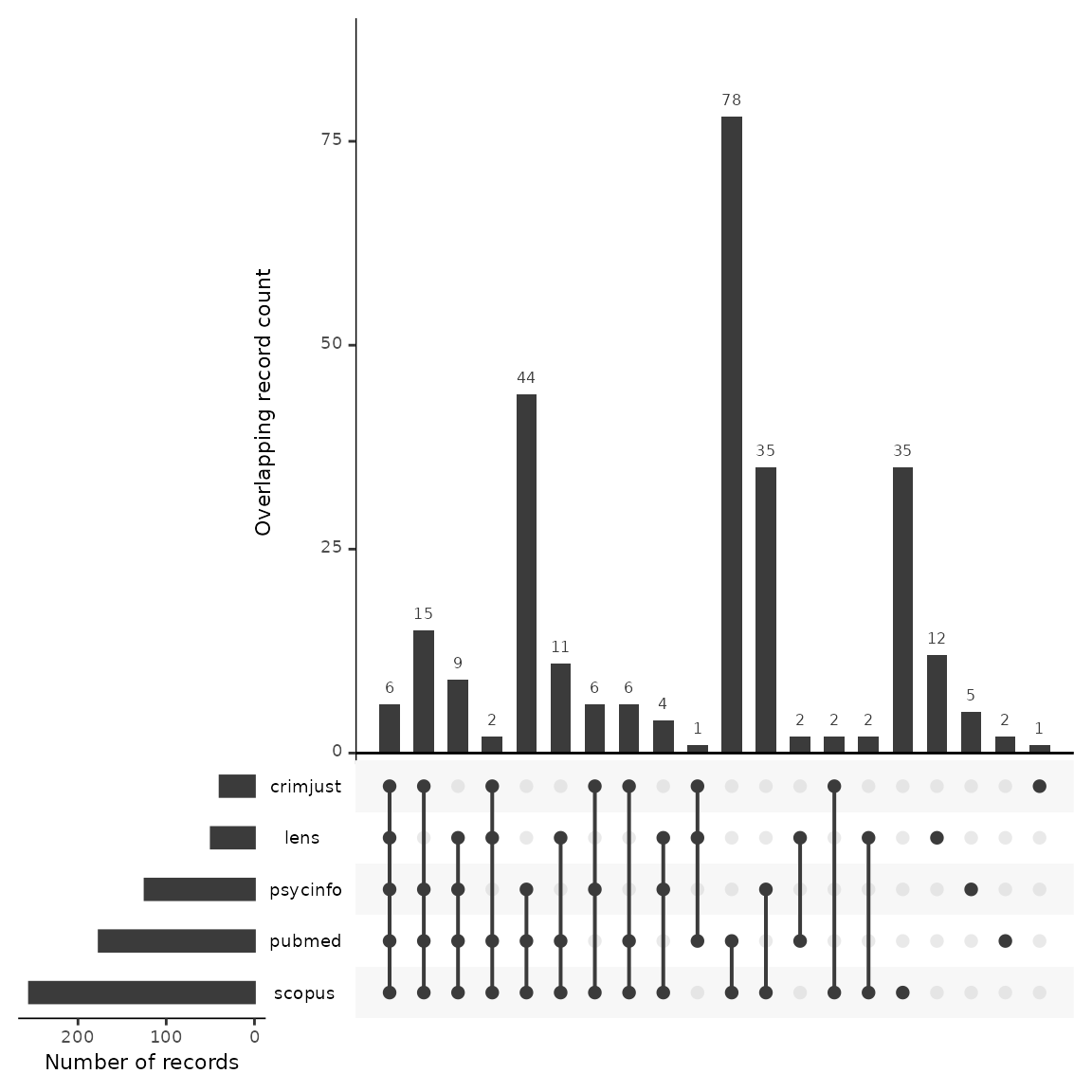
Bar plots of unique and shared records
Bar plot of numbers of records
Bar plots can be another way of looking at overlap and uniqueness of
databases contributions to a topic. We can use the output from the
count_unique function to produce a bar plot with
ggplot. Here we see a bar plot of the numbers of shared (pink)
and unique (green), or unshared, records by database.
#Generate bar plot of unique citations PER database as NUMBER
n_unique %>%
select(cite_source, duplicate_id, unique) %>% #remove label /other cols to prevent duplicated rows
ggplot(aes(fill=unique, x=cite_source)) +
geom_bar(position="stack", stat="count") +
xlab("") + ylab("Number of citations")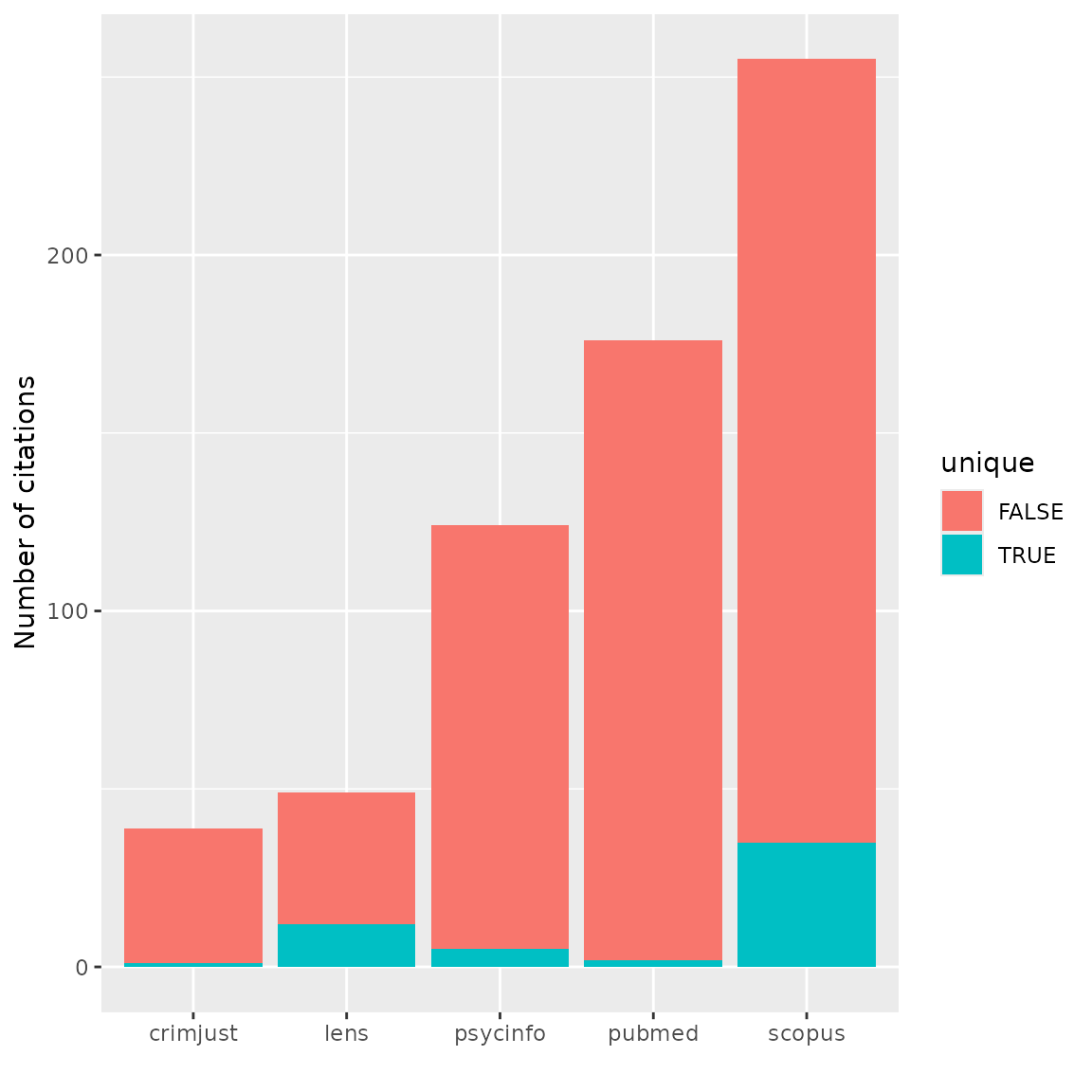
Bar plot of percentages of records
We can also look at proportions. Interestingly, Lens seems to have the greatest proportion of unique records on gambling harms.
#Generate bar plot of unique citations PER database as PERCENTAGE
n_unique %>%
select(cite_source, duplicate_id, unique) %>% #remove label /other cols to prevent duplicated rows
unique() %>%
group_by(cite_source, unique) %>%
count(unique, cite_source) %>%
group_by(cite_source) %>%
mutate(perc = n / sum(n)) %>%
ggplot(aes(fill=unique, x=cite_source, y=perc)) +
geom_bar(position="stack", stat="identity") +
xlab("") + ylab("Number of citations")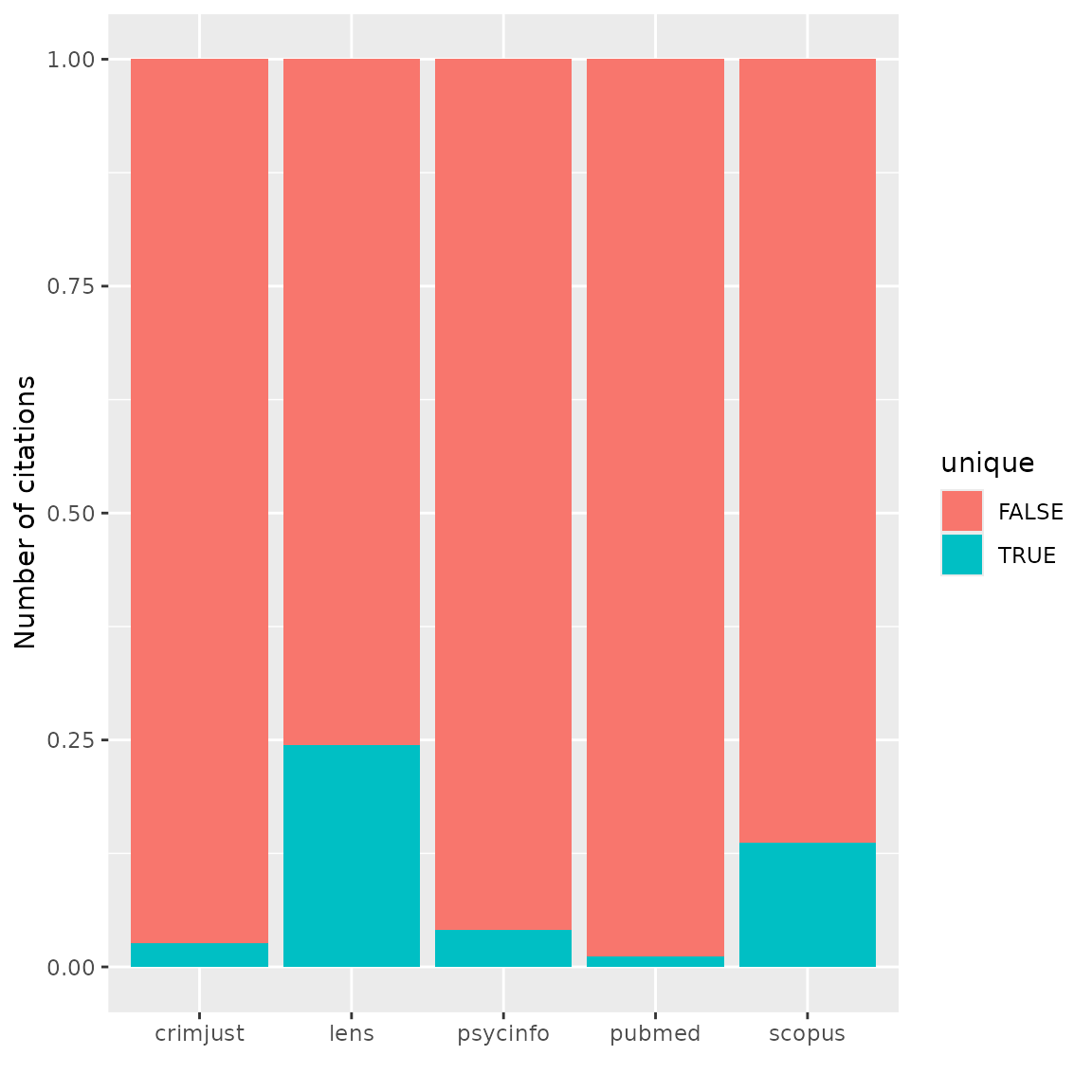
Bar plot with labels
And one more option: a labeled bar plot with dodged bars. This is useful if we have very small numbers of unique records compared to the overall number of records.
#Generate dodged bar plot Unique/Crossover PER Source with labels
n_unique %>%
select(cite_source, unique) %>%
ggplot(aes(fill=unique, x=cite_source)) +
geom_bar(position=position_dodge(width=0.5)) +
xlab("") + ylab("Number of citations") +
geom_text(stat="count", aes(label=..count..))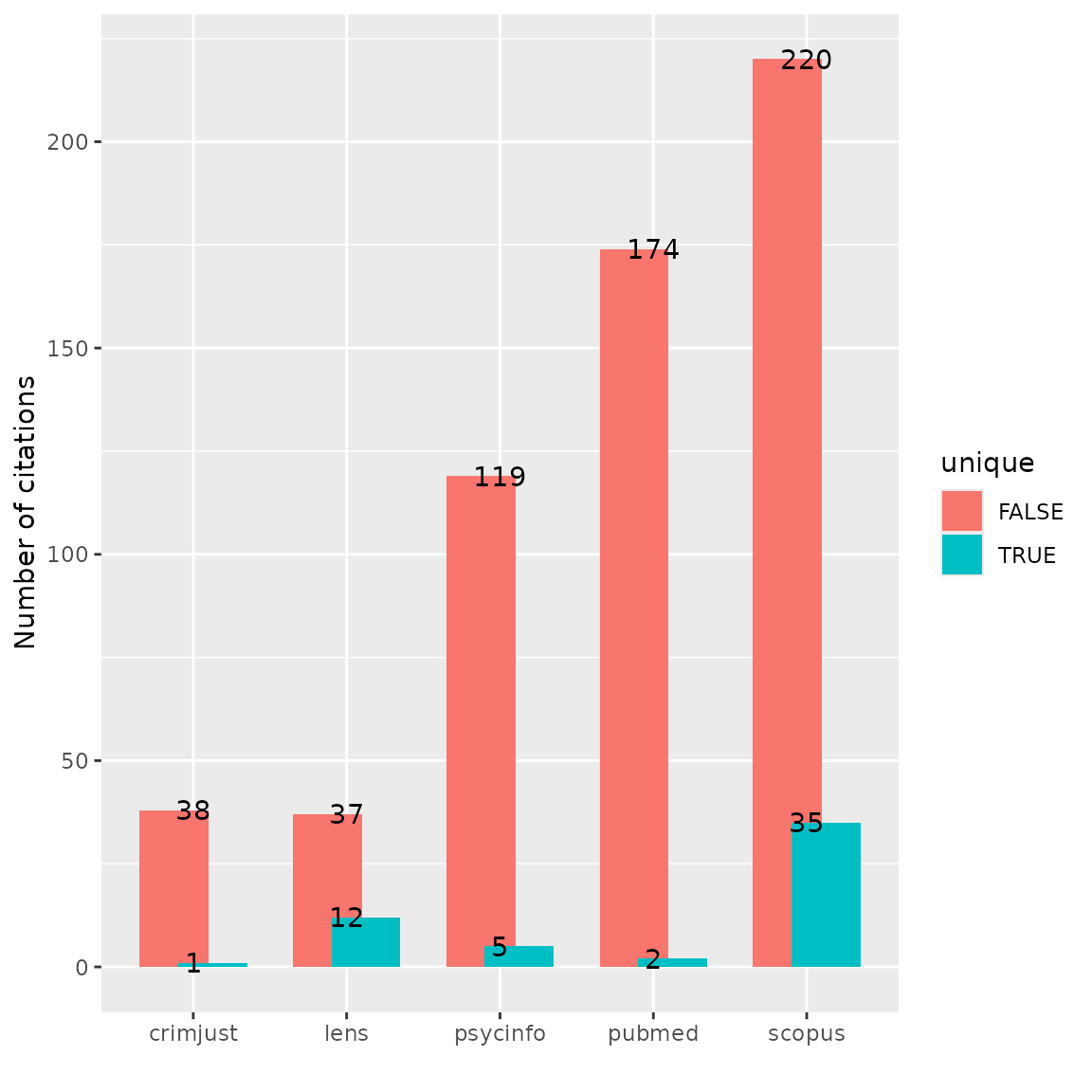
Analyzing unique contributions
When we’re trying to get a sense of relative database coverage for a
particular topic, in other words what a database contributes to a search
on a topic compared to other databases, we might want to look more
closely at the records that are only found in that database and not
appearing anywhere else. We can again make use of the output of the
count_unique function. We use the dplyr function
filter to find the unique records contributed by single
sources. We then use the inner_join function to regain the
bibliographic data by merging on record IDs with the unique_citations
dataframe we generated above in the deduplication process.
#Get unique records from each source and add bibliographic data
unique_lens <- n_unique %>% filter(cite_source=="lens", unique == TRUE) %>% inner_join(unique_citations, by = "duplicate_id")
unique_psycinfo <- n_unique %>%
filter(cite_source=="psycinfo", unique == TRUE) %>%
inner_join(unique_citations, by = "duplicate_id")
unique_pubmed <- n_unique %>%
filter(cite_source=="pubmed", unique == TRUE) %>%
inner_join(unique_citations, by = "duplicate_id")
unique_crimjust <- n_unique %>%
filter(cite_source=="crimjust", unique == TRUE) %>%
inner_join(unique_citations, by = "duplicate_id")
unique_scopus <- n_unique %>%
filter(cite_source=="scopus", unique == TRUE) %>%
inner_join(unique_citations, by = "duplicate_id")Analyze journal titles
Now we can take a deeper dive into the unique records contributed by each source. For example, let’s look at the top journal titles in Scopus that produced unique records on gambling harms not found in any other database.
#Analyze journal titles for unique records
scopus_journals <- unique_scopus %>%
group_by(journal) %>%
summarise(count = n()) %>%
arrange(desc(count))
#Use the knitr:kable function to print a nice looking table of the top 10 journals
kable(scopus_journals[1:10, ])| journal | count |
|---|---|
| International Gambling Studies | 5 |
| Current Addiction Reports | 3 |
| International Journal of Mental Health and Addiction | 3 |
| Journal of Gambling Issues | 3 |
| Computers in Human Behavior | 2 |
| Journal of Public Health (Germany) | 2 |
| Applied Research in Quality of Life | 1 |
| Canadian Journal of Addiction | 1 |
| Cognition and Addiction: A Researcher’s Guide from Mechanisms Towards Interventions | 1 |
| Critical Public Health | 1 |
Analyze publication years
We may also want to look at publication years of unique records. For example, perhaps one databases coverage is better for earlier research. Let’s look at the publication years of the 35 unique records from Scopus. We can see these are mostly very recent records, which may indicate a more up-to-date and current collection on gambling harms in the Scopus database.
#Group by year, count and produced a line graph
unique_scopus %>% group_by(year) %>%
summarise(count = n()) %>%
ggplot(aes(year, count, group=1)) +
geom_line() +
geom_point() +
xlab("Publication year") + ylab("Unique records")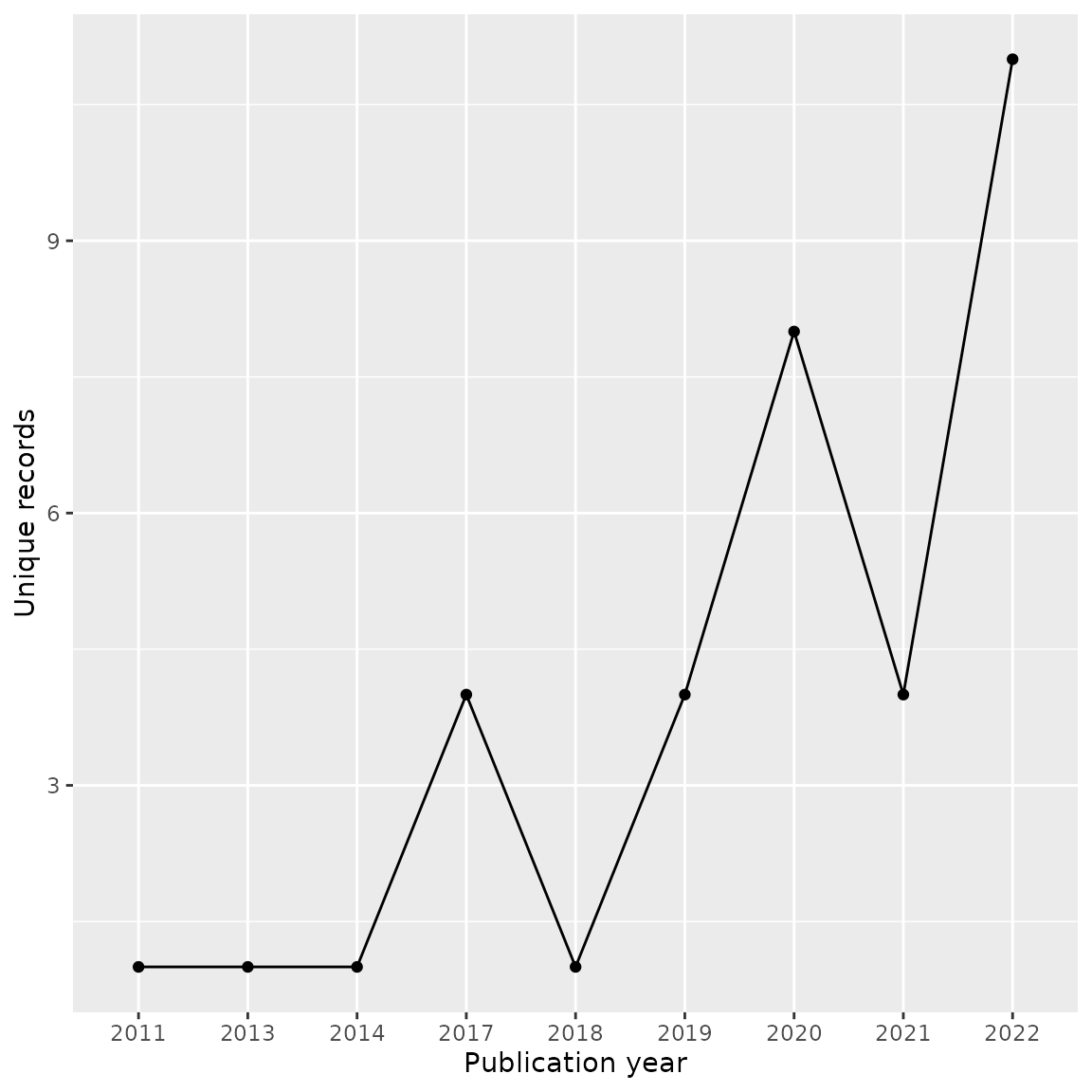
We can also compare publication years of unique records across each
database by using the facet_wrap feature of
ggplot.
#Combine all unique record dataframes into a single dataframe. Note that we'll leave Criminal Justice Abstracts out since there is only one unique record.
all_unique <- bind_rows(unique_scopus,unique_lens,unique_pubmed,unique_psycinfo)
#Group by year and source, count and produced a faceted line graph
all_unique %>% group_by(cite_source.x, year) %>%
summarise(count = n()) %>%
ggplot(aes(year, count, group=1)) +
geom_line() +
geom_point() +
facet_wrap(~ cite_source.x) +
xlab("Publication year") + ylab("Unique records")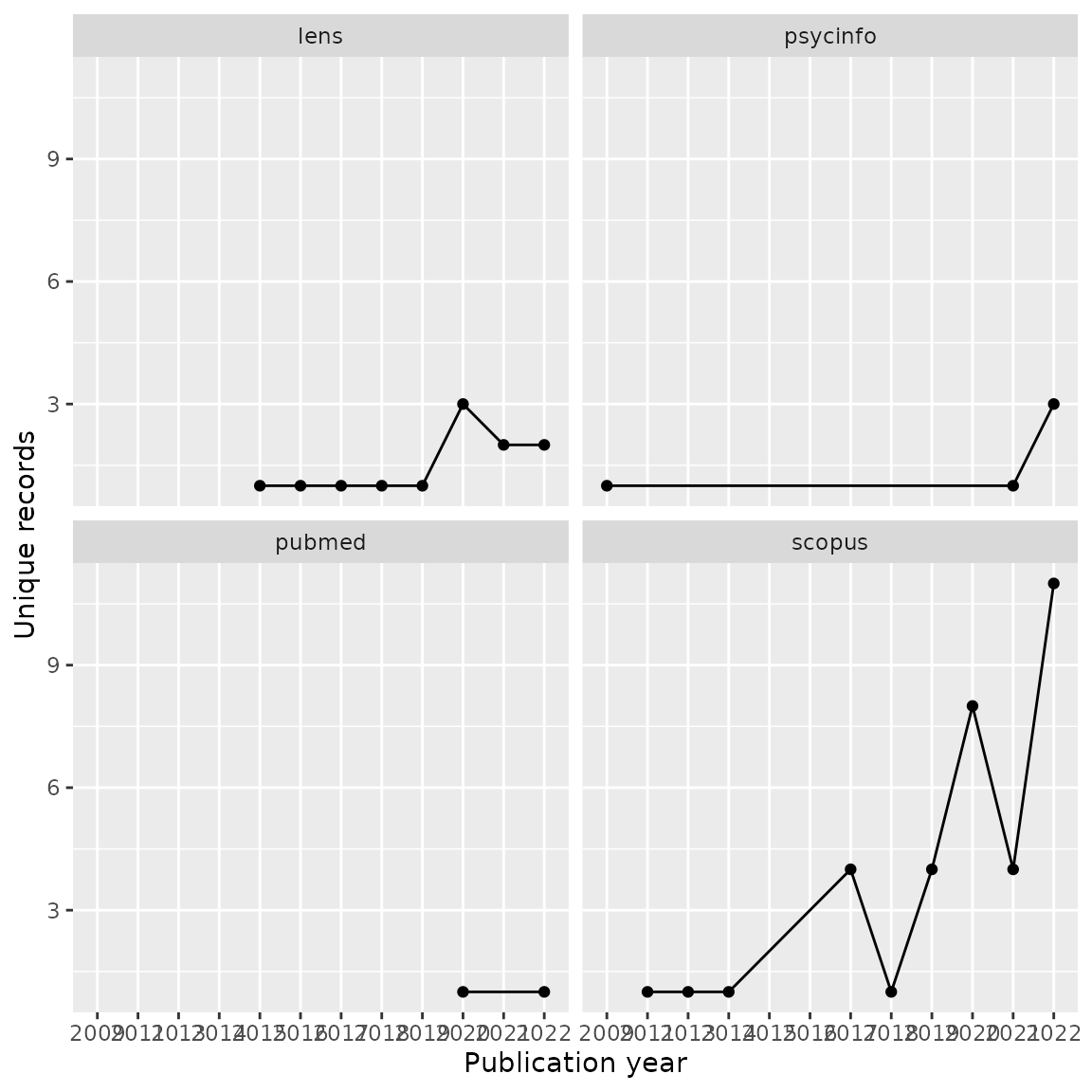
Exporting for further analysis
We may want to export our deduplicated set of results (or any of our
dataframes) for further analysis or to save in a convenient format for
subsequent use. CiteSource offers a set of export functions
called export_csv, export_ris or
export_bib that will save any of our dataframes as a .csv
file, .ris file or bibtex file, respectively. You can also reimport
exported csv files to pick up a project or analysis without having to
start from scratch, or after making manual adjustments to a file.
Generate a .csv file. The separate argument can be used to create separate columns for cite_source, cite_label or cite_string to facilitate analysis.
#export_csv(unique_citations, filename = "unique-by-source.csv", separate = "cite_source")Generate a .ris file and indicate custom field location for cite_source, cite_label or cite_string. In this example, we’ll be using Zotero, so we put cite_source in the DB field (which will appear as the Archive field in Zotero) and cite_labels into N1, creating an associated Zotero note file.
#export_ris(unique_citations, filename = "unique_citations.ris", source_field = "DB", label_field = "N1")Generate a bibtex file and include data from cite_source, cite_label or cite_string.
#export_bib(unique_citations, filename = "unique_citations.bib", include = c("sources", "labels", "strings"))Reimport a file generated with export_csv.
#reimport_csv("unique-by-source.csv")In summary
We can use CiteSource to evaluate coverage of different databases for a specific topic. In this example, we found that Scopus has the most content on gambling harms including the most unique content and the best coverage for earlier years. Lens also contributes a proportionally large amount of unique records, perhaps representing gray literature. An analysis of this sort can help determine which databases might be useful to search for an evidence synthesis project on a topic, or may be used to inform collection development decisions.